
Olá, bom dia.
Tudo bem? Espero que você que acompanha o meu blog ou esta acessando pela primeira vez possa estar bem. Para começar o outono, nada melhor que um simples post relacionado ao Microsoft SQL Server, não é mesmo?
Eu sou suspeito a dizer.
Seja bem-vindo ao @06 – O que Acontece?

Seguindo a tradição, antes de apresentar o quinto post, quero destacar alguns pontos sobre esta sessão, em especial o tipo de conteúdo que você leitor vai encontrar em cada post relacionado a ela:
1 – Os posts publicados nesta sessão envolvem um pouco do Micrososft SQL Server, na verdade o objetivo dela é tentar mostrar como ele SQL Server, o qual aqui eu vou denominar como caixa, pensa exclusivamente fora dela, ou seja, como este grandioso SGBD (Sistema Gerenciador de Banco de Dados) faz para que tenhamos nossos dados armazenados e apresentados em tela, em adicional como podemos de uma forma simples aprender, conhecer, desvendar os comportamentos realizados por ele além do uso das habituais ferramentas de administração: SQL Server Management Studio ou Azure Data Studio.
2 – Os posts, não apresentam o objetivo de demonstrar recursos, comandos, funcionalidades ou ensinar algo novo, na verdade eu quero tentar mostrar o que acontece muitas vezes quando por exemplo você esta processando um simples comando Select buscando milhões de dados em uma tabela, e o SQL Server Management Studio vai apresentando aos poucos os registros. Serão exclusivamente estes cenários, comportamentos e formas de atuação envolvendo o SQL Server e o ambiente que ele se encontra;
3 – Os posts, não terão uma estrutura padrão, na verdade, O que Acontece, foi idealizado da mesma forma que inicialmente começamos a pensar. Vamos reunindo conhecimentos, ideias, possibilidades, hipóteses, analisando alternativas, mensurando teorias, até tentar construir algo mais concreto;
4 – Não será estabelecido um calendário de publicação, ao contrário, sempre que algum pensamento fora da caixa pairar sobre a minha cabeça, ou coisas do meu dia-a-dia relacionados as minhas experiências profissionais ou acadêmicas, novos posts serão publicados, bem como, os atuais atualizados e corrigidos;
5 – Não vou me ater ao certo ou errado, melhor ou pior, tecnicamente perfeito ou melhor tecnicamente, o que eu quero é tentar como eu já destaquei ilustrar o que acontece do lado de fora do SQL Server, o que ele muitas vezes esta realizando e não temos ideia do que está acontecendo; e
6 – Vou tentar em cada post trazer uma ferramenta, aplicativo ou utilitário existente no próprio sistema operacional que possa nos ajudar a observar e entender o que está acontecendo de preferência em tempo real, em adicional, se possível utilizarei vídeos para elucidar de forma mais didática o objetivo do post.
Vamos começar nossa aventura
Seja mais uma vez bem-vindo ao @06 – O que Acontece – Comparativo de Armazenamento – Tabela com colunas calculadas – Dados Persistentes e Não Persistentes no Microsoft SQL Server.
Pensar no conteúdo de um novo post de acordo com sua respectiva sessão não é uma atividade que posso considerar como algo simples. Idealizar o conteúdo, imaginar o que pode ser compartilhado requer uma certa habilidade, algo que particularmente dizendo eu não tenho, bem como, não sei fazer isso facilmente, demoro vários dias para conseguir concretizar, mas estou sempre tentando.
Costumeiramente, de uma hora para outra a minha mente começa a juntar um pouco do conhecimento, experiência, pensamentos meio loucos, enfim, vou formulando alguns hipóteses, afim de tentar contextualizar mesmo que de forma vaga um rascunho.
Hoje não foi diferente, acordei como de costume bem cedinho, pensando, pensando, até encontrar algum assunto mesmo que possa parecer simples, mas que ao mesmo tempo traga novos conhecimentos ou possa responder alguma dúvida.
Neste momento estava surgindo o sexto post da sessão O que Acontece.
Tabelas com Colunas Calculadas Persistentes e Não Persistentes
Dentre as diversas maneiras que podemos utilizar o Microsoft SQL Server, a existência das colunas calculadas, funcionalidade que nos permite diretamente na construção de nossas tabelas implementar operações matemáticas e formas de materializar os dados que possam ser gerados por ele em tempo de execução.
Por padrão o uso das colunas calculadas, para muitos também conhecidas como colunas computadas pode apresentar comportamentos diferentes ao longo do processamento de um conjunto de dados, os quais podem ou não persistir, ou seja, existir fisicamente em disco.
Através do simples comparativo a ser apresentado neste post, você poderá observar este diferença comportamental, tanto na forma de armazenamento dos dados, como também, no espaço ocupado em disco rígido e principalmente na definição e uso do plano de execução adotado pelo Microsoft SQL Server. Para tal comparativo, utilizaremos os Scripts apresentados abaixo, respeitando sua ordem de declaração:
— Script 1 – Montando o Ambiente —
-- Criando o Banco de Dados --
Create Database Comparacao
Go
-- Acessando --
Use Comparacao
Go
-- Criando a TabelaDadosPersistentes --
Create Table TabelaDadosPersistentes
(Codigo Int Primary Key Identity(1,1) Not Null,
Descricao Varchar(30) Null,
Valor SmallInt Not Null,
Valor2 As (Valor/2) persisted, -- Materializando o armazenamento dos dados --
Valor3 As (Valor/3) persisted,
Valor4 As (Valor/4) persisted,
Valor5 As (Valor/5) persisted)
Go
-- Criando a TabelaDadosNaoPersistentes --
Create Table TabelaDadosNaoPersistentes
(Codigo Int Primary Key Identity(1,1) Not Null,
Descricao Varchar(30) Null,
Valor SmallInt Not Null,
Valor2 As (Valor/2),
Valor3 As (Valor/3),
Valor4 As (Valor/4),
Valor5 As (Valor/5))
Go— Script 2 – Inserindo os dados nas Tabelas —
-- Inserindos valores fixos - TabelaDadosPersisentes --
Insert Into TabelaDadosPersistentes (Descricao, Valor)
Values ('Arroz', 10), ('Feijão', 20), ('Ovo', 30), ('Tomate', 40), ('Carne', 50), ('Bolacha', 60), ('Leite', 70), ('Suco', 80)
Go
-- Inserindos valores fixos - TabelaDadosNaoPersisentes --
Insert Into TabelaDadosNaoPersistentes (Descricao, Valor)
Values ('Arroz', 10), ('Feijão', 20), ('Ovo', 30), ('Tomate', 40), ('Carne', 50), ('Bolacha', 60), ('Leite', 70), ('Suco', 80)
GoAo observarmos o Script 1, a única diferença entre a estrutura das tabelas, consiste no uso da propriedade Persisted, sendo está responsável em orientar o SQL Server na forma como os dados devem ser fisicamente armazenados, ou então gerados em tempo de execução.
— Script 3 – Apresentando a Estrutura física e lógica das tabelas —
-- Consultando a estrutura física e lógica - TabelaDadosPersistentes --
SP_Help 'TabelaDadosPersistentes'
Go
-- Consultando a estrutura física e lógica - TabelaDadosNaoPersistentes --
SP_Help 'TabelaDadosNaoPersistentes'
GoAs Figura 1 e 2 apresentam a estrutura física de cada tabela, com base, no trecho de código apresentado no Script 3:
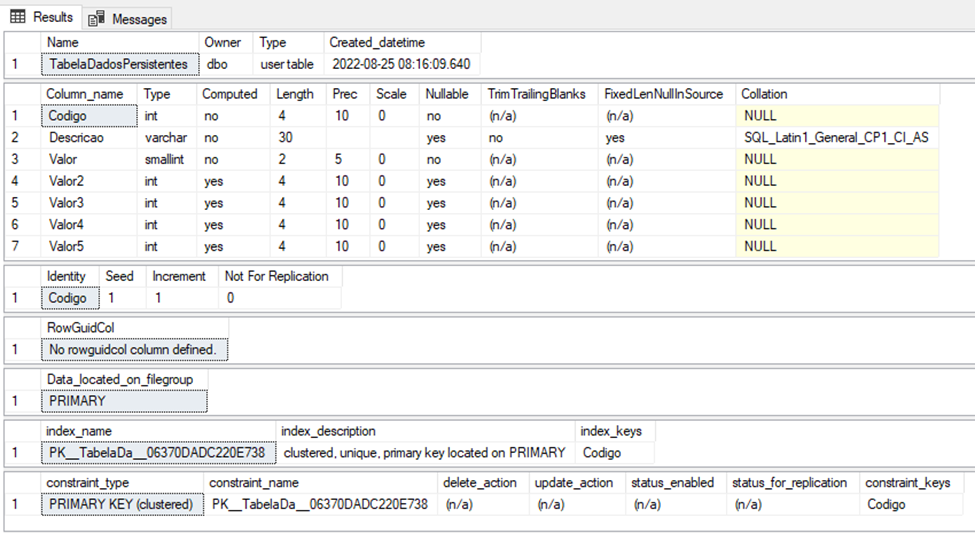
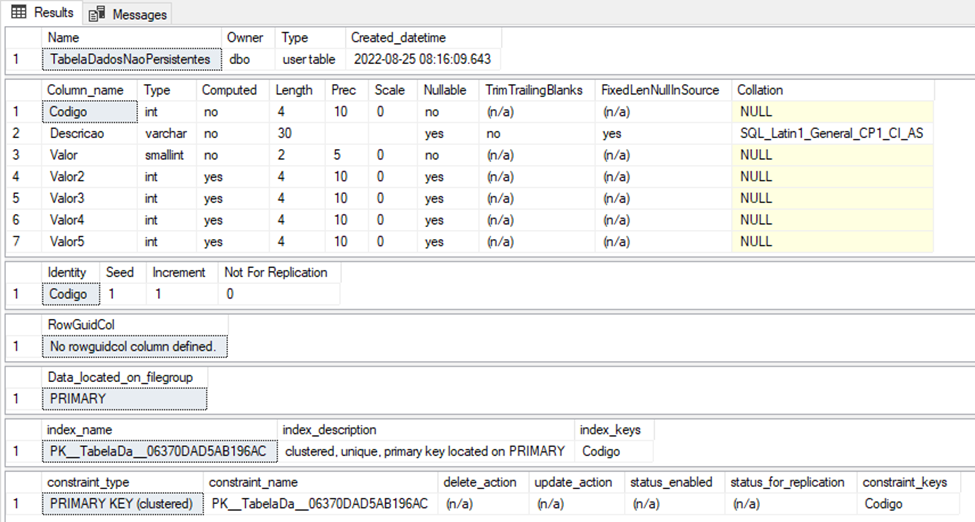
Nosso próximo passo, consiste em identificar a segunda diferença entre as duas tabelas, mais especificamente falando, a maneira como cada tabela realiza a distribuição de dados de forma física, levando-se em consideração a área reservada para alocação, área de dados, índice e até mesmo área não utilizada.
As Figuras 3 e 4 vão nos ajudar a observar estas diferenças:


Observando as Figuras 3 e 4, fica nítido a existência de diferenças nas distribuição das áreas de alocação de espaço em disco adotada por cada tabela, de forma lógica, a TabelaDadosPersistentes tem uma área reservada para utilização dos dados 53% maior que a TabelaDadosNaoPersistente, mesmo as tabelas tendo a quantidade de registros lógicos iguais, ou seja, um total de 2.337 (Duas mil, trezentas e trinta e sete) linhas. Todos os demais indicadores apresentam também, alguma diferença em relação o seu total de área utilizada.
Nosso último passo, está relacionado as diferenças que podem existente no plano de execução adotado pelo SQL Server para pesquisar, identificar, filtrar e apresentar os dados para usuário de acordo com as requisições a ele encaminhadas. Para ajudar a gerar estas diferenças, iremos utilizar o Script 4, o qual nos permitirá inserir uma pequena massa de dados pseudoaleatórios
— Script 4 – Inserindo uma pequena massa de dados pseudoaleatórios —
-- Inserindo os mesmos valores pseudoaleatórios - TabelaDadosPersistentes e TabelaDadosNaoPersistentes --
Declare @Contador SmallInt, @NumeroSorteado Int, @DescricaoSorteada Varchar(30), @ValorSorteado Int
Set @Contador = 1
Set @NumeroSorteado = Rand()*10000 -- Sorteando a quantidade aleatória de registros até o número 10000 --
While @Contador <= @NumeroSorteado
Begin
Set @DescricaoSorteada = (Concat(Char(Rand()*96), Char(Rand()*96), Char(Rand()*96), Char(Rand()*96), Char(Rand()*96))) -- Concatenado caracteres para formar a descricao aleatória --
Set @ValorSorteado = Rand()*100 -- Sorteando o número para a coluna valor --
-- Inserindo os valores --
Insert Into TabelaDadosPersistentes (Descricao, Valor)
Values (@DescricaoSorteada, @ValorSorteado)
Insert Into TabelaDadosNaoPersistentes (Descricao, Valor)
Values (@DescricaoSorteada, @ValorSorteado)
Set @Contador = @Contador + 1 -- Incrementando o contador --
End
GoApós nossa pequena massa de dados pseudoaleatórios ter sido executada, vamos fazer uso do comando Select, afim de solicitar o retorno em tela de todos os registros lógicos pertencentes a cada tabela, vamos então utilizar o Script 5.
— Script 5 – Apresentando todos os registros lógicos —
-- Consultando os dados, realizando a comparação entre os planos de execução --
-- Ativar Plano de Execução - CTRL+M --
Select Codigo, Descricao, Valor, Valor2, Valor3, Valor4, Valor5 From TabelaDadosPersistentes
Go
Select Codigo, Descricao, Valor, Valor2, Valor3, Valor4, Valor5 From TabelaDadosNaoPersistentes
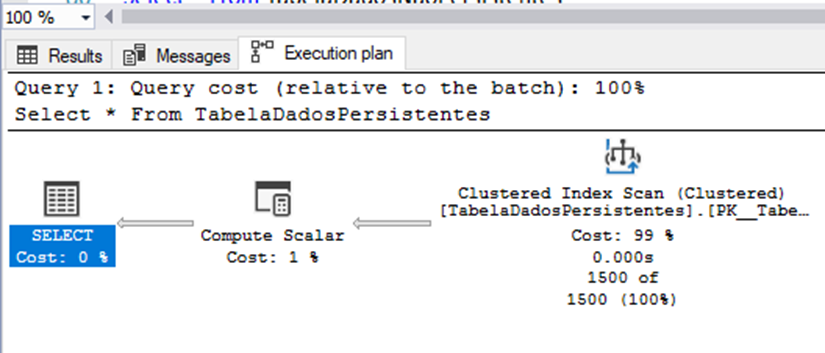
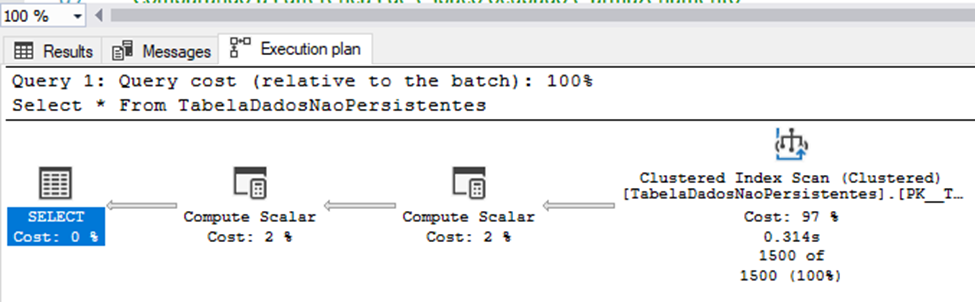
GoAs Figuras 5 e 6, ilustram as diferenças existentes em cada plano de execução, tendo como base os comandos Selects executados anteriormente através do Script 5:
Observação: Não se esqueça de ativar a apresentação/utilização do plano de execução e seus operadores.
De forma simples, podemos observar que no plano de execução apresentado na Figura 6, o SQL Server tem a necessidade de utilizar duas vezes o operador Compute Scalar, sendo este operador responsável em gerar e manipular os valores pseudoaleatórios para cada coluna calculada, como também, fazer com que os mesmos possam ser alocados em memória para posterior reaproveitamento por parte do operador Select.
Por fim, através do conjunto de dados inseridos em ambas as tabelas, as quais possuem a mesma estrutura lógica mas com uma pequena diferença na forma de manipular os dados relacionados com as colunas calculadas: Valor2, Valor3, Valor4 e Valor5.
Fica evidente que a TabelaDadosPersistentes, apresenta um valor maior na área de alocação definida para armazenamento de dados, em decorrência o uso da propriedade persisted definida no momento da criação das colunas calculadas destacadas anteriormente.
A propriedade persisted faz com que os dados retornados após a cálculo realizados para as respectivas colunas fiquem fisicamente armazenados em disco, comportamento contrário quando se cria colunas calculadas mas que não devem realizar a persistência dos dados.
Neste caso, os valores serão sempre calculados todas as vezes que as respectivas colunas forem manipuladas nas ações realizadas para o processamento comando Select, as quais podem envolver a criação de um novo plano de execução, atualização de um plano já existente, até o retorno dos dados em tela.
Todavia, a utilização ou não da propriedade persisted deve sempre ser avaliada, em conjunto com a equipe de DBAs, Engenheiros de Bancos de Dados, Administradores de Servidores e desenvolvedores, afim de se identificar a melhor estratégia relacionada a forma de armazenamento, processamento, manipulação e apresentação dos dados.
Desta forma, chegamos ao final do @06 – O que Acontece – Comparativo de Armazenamento – Tabela com colunas calculadas – Dados Persistentes e Não Persistentes no Microsoft SQL Server.
Caso queira identificar de forma mais elaborada as diferenças de espaço de armazenamento ocupada por cada tabela, execute o Script 6 a seguir:
— Script 6 – Comparando as diferenças de espaço ocupado e armazenamento —
Select s.Name As 'Schema',
t.Name As 'Nome da Tabela',
p.rows As 'Quantidade de Registros',
Cast(Round((Sum(a.used_pages) / 128.00), 2) As Numeric(36, 2)) AS 'Espaço Ocupado Mbs',
Cast(Round((Sum(a.total_pages) - SUM(a.used_pages)) / 128.00, 2) As Numeric(36, 2)) AS 'Espaço Não Ocupado Mbs',
Cast(Round((Sum(a.total_pages) / 128.00), 2) AS NUMERIC(36, 2)) As 'Total de Área de Armazenamento reservada'
From sys.tables t Inner Join sys.indexes i
On t.object_id = i.object_id
Inner Join sys.partitions p
On i.object_id = p.object_id
And i.index_id = p.index_id
Inner Join sys.allocation_units a
On p.partition_id = a.container_id
Inner Join sys.schemas s
On t.schema_id = s.schema_id
Group By t.Name, s.Name, p.Rows
Order By s.Name, t.Name
GoEspero que este conteúdo possa ser útil, o qual teve o objetivo de apresentar um comparativo e as diferenças comportamentos entre tabelas que utilizam colunas calculadas de forma persistente ou não persistente.
E aí gostou deste post? Espero que sim.
Mais uma vez obrigado por sua visita, aproveite para acessar as outras sessões existentes no meu blog.
Um forte abraço
