
Olá, boa dia!
Seja bem-vindo a mais um post da sessão “Contando História com Dados“.
Nesta nova sessão, você vai encontrar posts relacionados a área de dados, destacando ao longo dos anos como este elemento atualmente reconhecimento como o mais importante em nossas vidas, conseguiu evoluir, conquistar o seu espaço, tornando-se cada vez mais vital para nossa evolução.
Em adicional, estarei compartilhando sempre que possível, um documento, apresentação ou resumo do conteúdo aqui compartilhado, o qual conterá o meu ponto de vista, conhecimento e aprendizados obtidos ao longo dos estudos realizados para elaboração do referido post.
Neste terceiro post, destaco de forma breve a técnica para avaliação da capacidade de generalização de modelos matemáticos conhecida com Validação Cruzada K – Folds.
Introdução
A validação cruzada é uma técnica para avaliar a capacidade de generalização de um modelo, a partir de um conjunto de dados, amplamente empregada em problemas onde o objetivo da modelagem é a predição. Tem como objetivo estimar o quão preciso é este modelo na prática, ou seja, o seu desempenho e assertividade para um novo conjunto de dados (LING, 2019).
Uma das maneiras de fazer a divisão desses dados é usando o método holdout, o qual consiste em dividir os dados em 70-30 de maneira aleatória, ou seja, 70% dos dados para a fase de treinamento e 30% para a fase de teste ou checagem.
A desvantagem de usar essa técnica, está condicionada a possibilidade de selecionar uma porção de dados para treino, teste ou checagem que são muito parecidas tendo uma boa avaliação do modelo. Nesse caso, porém, quando colocamos o modelo em produção os dados novos são muito diferentes dos dados já conhecidos pelo modelo, o que nos gera péssimos resultados, praticamente tornando inutilizável este conjunto de dados (WONG, 2017).
Outra possibilidade para se evitar problemas relacionados a aleatoriedade dos dados, consiste na criação de grupos, estes formados por conjuntos de dados, como forma de divisão. Esta alternativa surge como técnica que visa eliminar a aleatoriedade, reduzir a variância, afim de estabelecer um resultado mais robusto. A única desvantagem apresentada por esta técnica, está diretamente relacionada a possíveis impactos no que se refere ao tempo de processamento, mais especificamente ao desempenho (LING, 2019).
Na possibilidade de a base de dados selecionada apresentar uma grande quantidade (milhões) de observações a serem analisadas, o tempo de processamento demandado pela validação cruzada poderá se tornar um pouco mais demorado, proporcionando um possível impacto ou demora no que se refere a apresentação dos resultados.
Como forma de exemplificar, estarei destacando o uso da técnica de validação cruzada k-folds, a mesma foi utilizada na elaboração do meu estudo de análise de queimadas ocorridas no Brasil ao longo dos últimos anos, como fonte de aprendizado para construção de uma máquina de aprendizada capaz de predizer e classificar tendo como base a análise de dados disponibilizadas pelo INPE combinados com os dados do INMET.
Estes dados permitiram estabelecer uma forma de alertar sobre uma possível nova ocorrência de queimada, ou eminência de um novo foco de calor provocado pela falta de chuvas em uma determinada área de estudos.
Aplicando a Validação Cruzada
Para o cenário de estudo escolhido, foi definida a utilização de k (folds = 5), ou seja, 5 (cinco) que representa a quantidade de agrupamentos de dados criados, considerando 4 grupos combinados que formam um único grupo selecionado para a fase de treinamento de dados, e grupo restante para a fase de checagem.
Do total de 1286 observações identificadas na fase de preparação dos dados, 900 foram distribuídas em 5 (cinco) grupos compostos obrigatoriamente por 180 observações, as quais foram selecionadas de forma aleatória, não se repetindo observações já selecionadas em outros grupos no momento da composição do grupo atual.
A definição da quantidade de números de iterações a serem utilizadas, foi estabelecida tendo como base a quantidade de folds, neste caso 5-folds, com objetivo de permitir oprocessamento, análise e apresentação dos resultados.
Para posterior comparação entre os valores obtidos referentes aos grupos de treinamentos, para com os valores de cada grupo de checagem, realizando está comparação ao término de cada iteração.
A Figura 1 ilustra o conjunto de grupos de treinamentos e checagens definidos para serem submetidos ao uso da validação cruzada 5-folds.
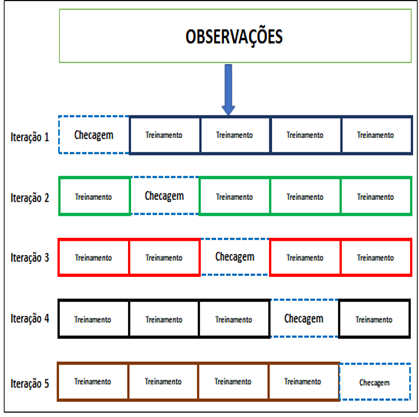
Vale ressaltar, que cada grupo foi nomeado como TrainingGroup (grupo de treinamento), acrescentando-se uma combinação numérica que representa a junção dos grupos que formam o respectivo grupo de treinamento. A Figura 2 apresenta um exemplo desta nomenclatura.

Podemos dizer que o TrainingGroup2345 representa a junção dos grupos de treinamento: 2, 3, 4 e 5 totalizando o número 720 observações. A Tabela 1 descreve todos os grupos de treinamentos criados para serem aplicados na validação cruzada.
Tabela 1 – Grupos de Treinamento
| Nome do Grupo | Número dos Grupos Combinados | Número do Grupo Selecionado para Checagem |
| TrainingGroup2345 | 2, 3, 4 e 5 | 1 |
| TrainingGroup1345 | 1, 3, 4 e 5 | 2 |
| TrainingGroup1245 | 1, 2, 4 e 5 | 3 |
| TrainingGroup1234 | 1, 2, 3 e 5 | 4 |
| TrainingGroup1235 | 1, 2, 3 e 4 | 5 |
Download
Artigo – Hybrid Models Applied to Create a Classification Index of Fire Risk Levels in Brazil
Projeto – Data Waherouse – Análise de Queimadas – Scripts
Projeto – Data Waherouse – Análise de Queimadas – Validação Cruzada
Projeto – Data Waherouse – Análise de Queimadas – Fonte de Dados
Projeto – Data Warehouse – Análise de Queimadas – Dados – Modelos Matemáticos
Referências
Galvão, Jr. P. A., Roveda, S. R. M. M., & Vieira, H. E. (2022). Hybrid models applied to create a classification index of fire risk levels in Brazil. Brazilian Journal of Environmental Sciences (online) 1–11. https://doi.org/10.5327/Z2176-94781286
LING, H.; QIAN, C.; KANG, W.; LIANG, C.; CHEN, H. Combination of Support Vector Machine and K-Fold cross validation to predict compressive strength of concrete in marine environment. https://doi.org/10.1016/j.conbuildmat.2019.02.071, 2019.
WONG, T.T. Parametric methods for comparing the evaluated by k-fold cross validation on multiple data sets. https://doi.org/10.1016/j.patcog.2016.12.018, 2017.
Agradecimento
Obrigado por sua visita a mais este post do meu blog!
Espero que este post e todos os demais aqui compartilhados possam lhe ajudar ao longo das mais diversas necessidades da sua vida profissional e acadêmica.
“Aproveite, para viver cada dia, observando como você pode transformá-la em uma nova história repleta de dados.“
Um forte abraço.
